https://databricks.com/try-databricks
Try Databricks - Unified Data Analytics Platform for Data Engineering
Discover why businesses are turning to Databricks to accelerate innovation. Try Databricks’ Full Platform Trial free for 14 days!
databricks.com
1. 가입 화면
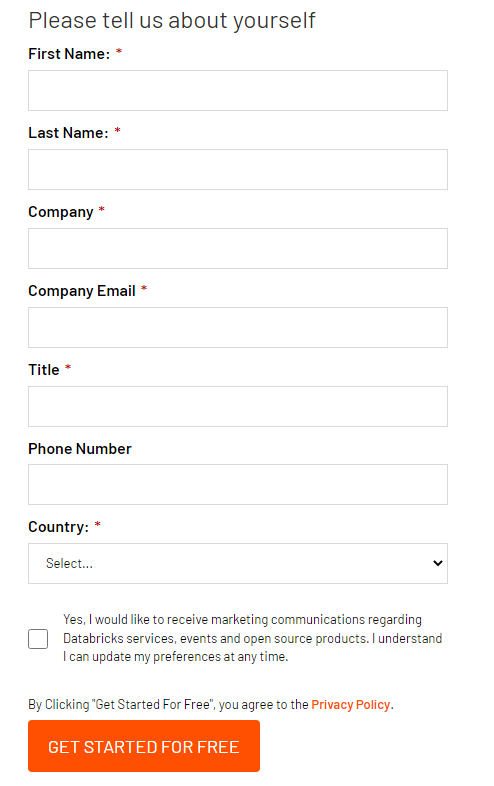
이름, 성, 회사명, 이메일, 직위, 나라(Korea, Republic of)를 선택 후 Get Start 클릭
2. 클라우드 선택
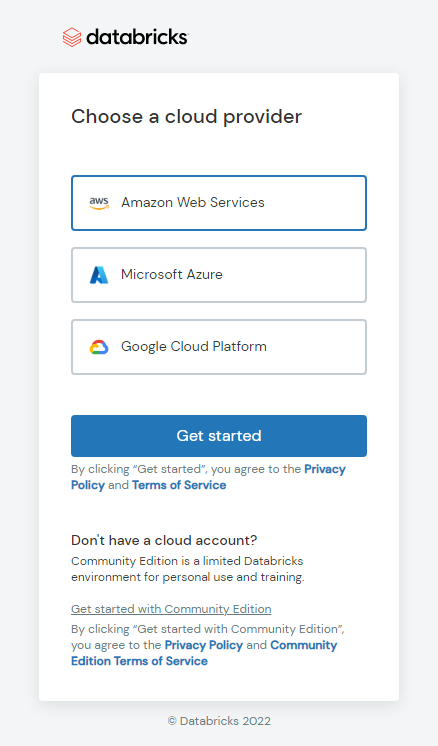
AWS, GCP, AZURE 등 사용하는 클라우드 플랫폼이 있다면 선택해주고,
만약 없다면 하단에 커뮤니티 버전(Get started with Community Edition)으로 선택.
3. 클러스터 생성
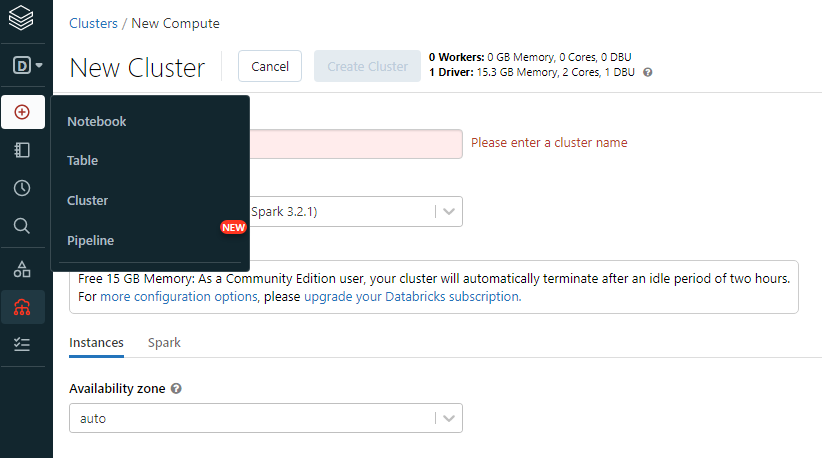
좌측에서 클러스터 생성을 클릭하고 생성할 클러스터명을 입력해준 뒤 Create Cluster 버튼을 눌러주면 생성 가능.
4. 노트북 생성
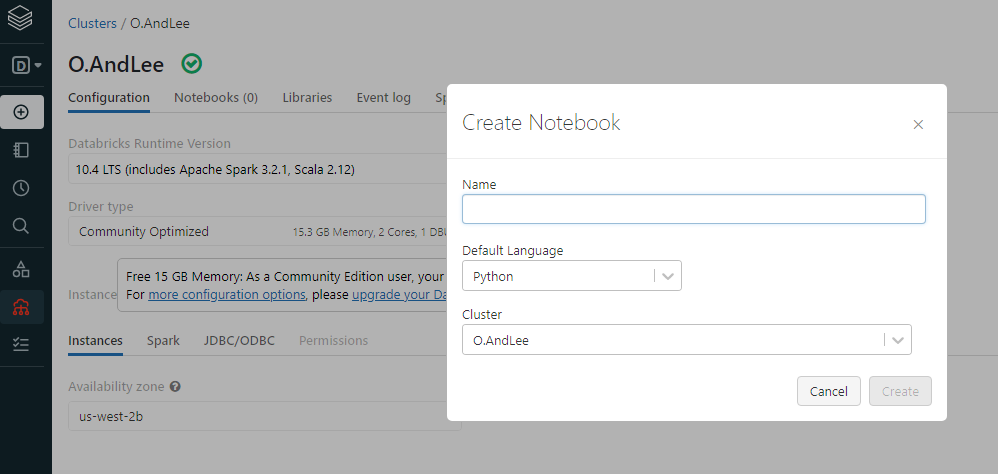
마찬가지로 좌측에서 노트북 생성을 클릭하고 노트북 명을 입력한 뒤 생성.
5. 파이스파크 불러오기
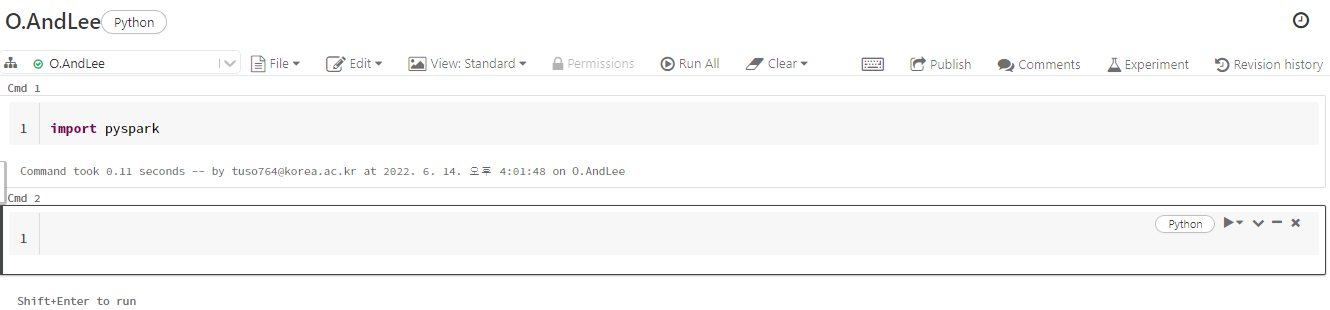
주피터 노트북이나 구글 코랩 같은 느낌의 노트북 페이지가 생성된다.
먼저, 파이스파크를 불러온다.
import pyspark
6. 테이블 생성
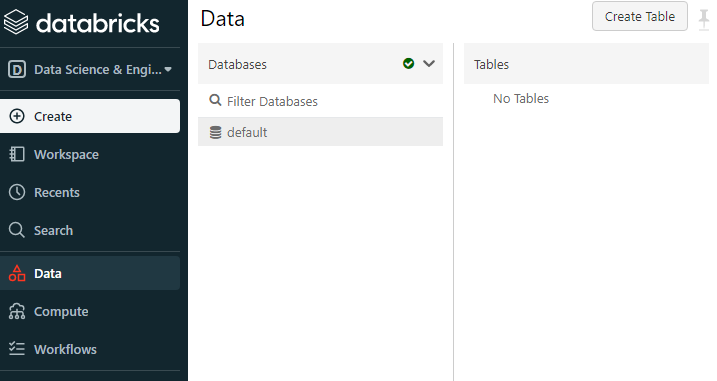
데이터 탭에서 테이블을 생성할 수 있다.
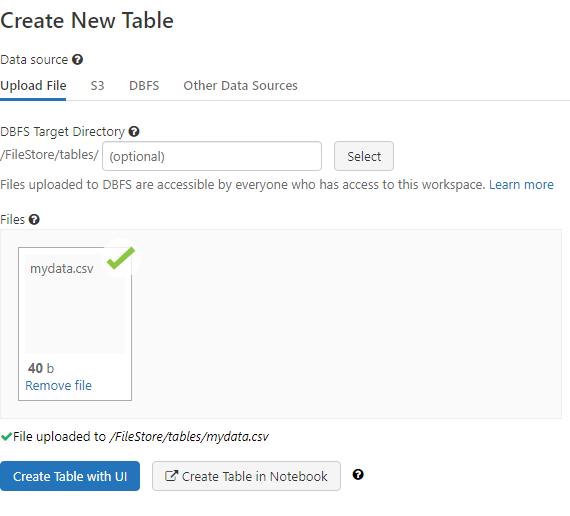
직접 파일을 업로드하거나 AWS의 S3과 연동시킬 수도 있고 혹은 다른 DBMS와 연동도 가능하다.
예제파일.
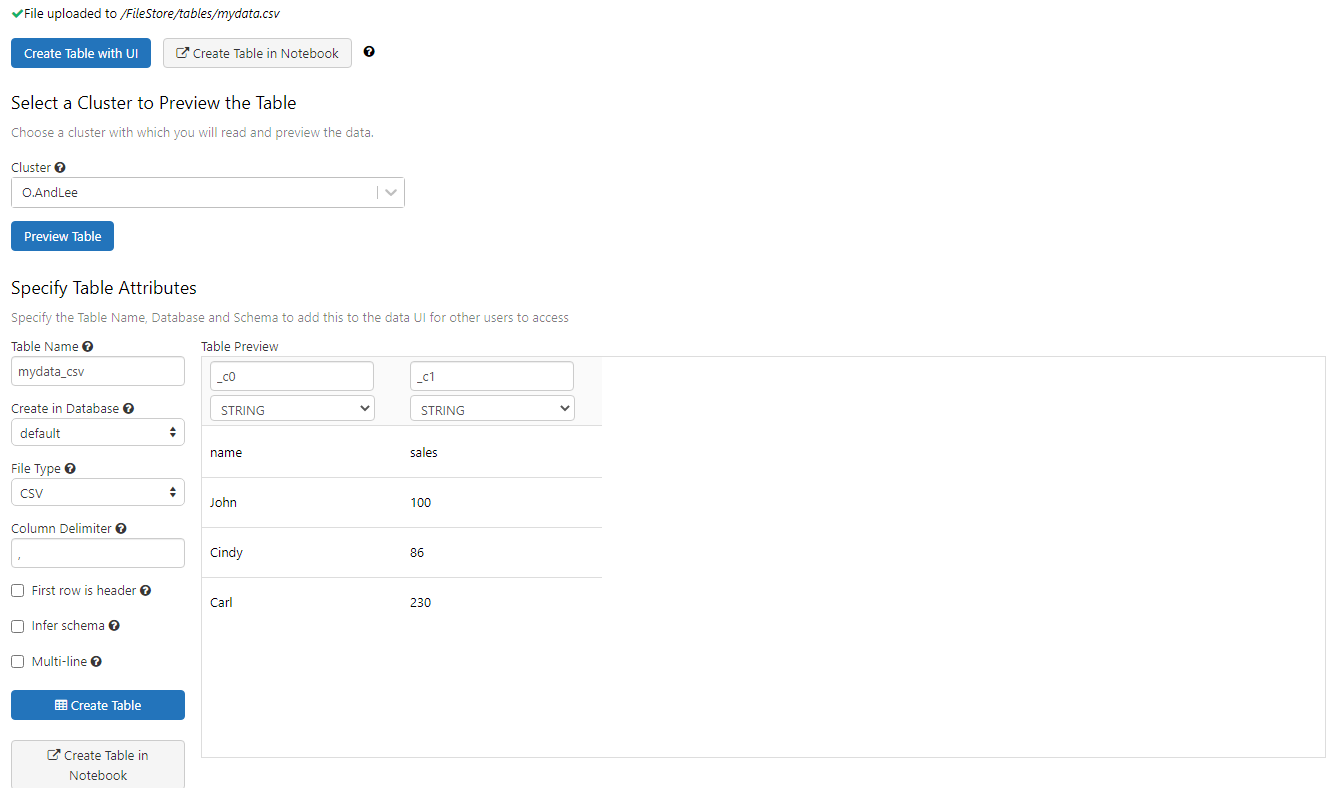
기존에 만들어둔 클러스터를 선택하고 미리보기를 하면 테이블 명 등 상세 특성을 설정할 수 있다.
- First row is header를 체크
- name 열은 String이 맞으므로 그대로 두고
- sales열은 숫자이므로 int로 바꿔준다.
세팅을 다 했다면 Create Table을 눌러서 테이블을 생성해준다.
7. 노트북에서 테이블을 데이터프레임으로 불러오기
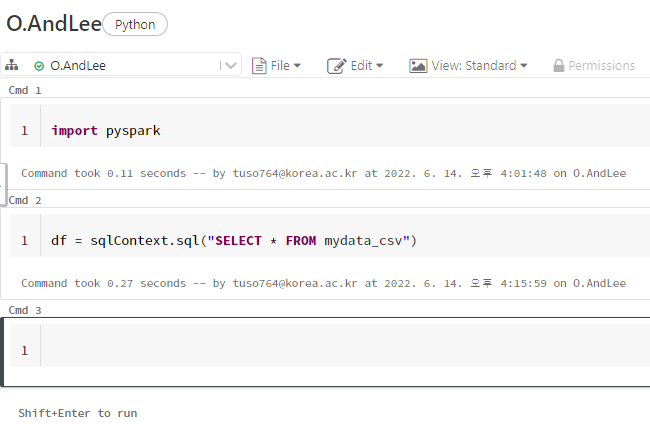
SQL 명령어를 통해서 테이블을 불러올 수 있다.
df = sqlContext.sql("SELECT * FROM mydata_csv")
8. 불러온 데이터 확인
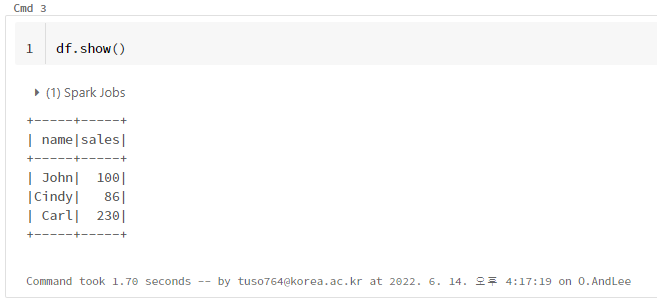
df.show()